
Você já passou por situações que seu sistema estava lento, demorando a carregar as telas? Será que um cache poderia resolver seu problema?
Nesse post eu faço uma pequena introdução ao cache de 2º nível com JPA e Hibernate. Ele pode te ajudar a resolver alguns problemas de performance, reduzindo o número de consultas ao banco de dados.
Eu criei uma aplicação web com PrimeFaces, CDI e JPA com Hibernate para demonstrar como o número de consultas ao banco diminui se você ativar o cache de 2º nível. Apesar da aplicação demonstrar uma utilização em um contexto real, você precisa de algumas configurações a mais para colocar em produção.
A aplicação faz o cadastro de uma nota fiscal eletrônica no banco de dados. Para isso, precisamos selecionar o estado e a cidade que será emitida a nota.
Nesse exemplo não adicionei nenhum cálculo específico para cidade ou estado, apenas quero focar na quantidade de consultas que serão feitas no banco de dados, quando clicarmos no botão “Salvar”. Veja o print da tela abaixo:
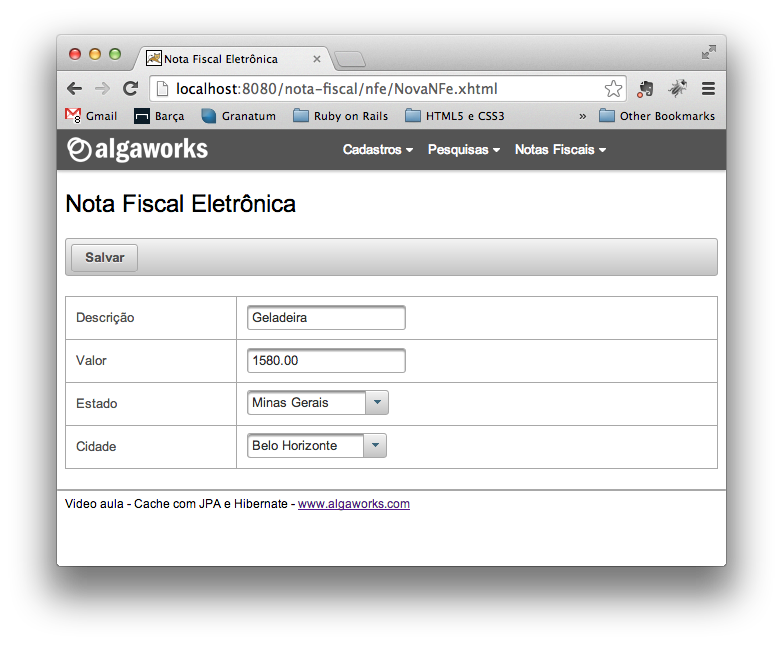
Repare que existem duas caixas de seleção. Uma para estado e outra para cidade. O que eu quero melhorar aqui é, quando clicar em “Salvar”, o JSF precisa converter esses campos para objetos antes de salvar a nota fiscal. Ele faz essa conversão executando uma consulta no banco de dados através dos converters. O que iremos alcançar é simples, essas consultas serão todas feitas no cache e não no banco de dados.
O que é necessário para ativar o cache de 2º nível? São basicamente dois passos. O primeiro é adicionar no persistence.xml a propriedade abaixo:
<property name="hibernate.cache.region.factory_class"
value="org.hibernate.testing.cache.CachingRegionFactory"/>
Repare que estou utilizando uma classe de teste do Hibernate para criar a região do cache. Não é recomendado para produção, apenas para nós entendermos os benefícios de se utilizar o cache.
O segundo passo consiste em anotar o que gostaríamos de colocar em cache. Veja a entidade Estado abaixo:
@Entity
@Table(name = "estado")
@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public class Estado implements Serializable {
private static final long serialVersionUID = 1L;
private Long codigo;
private String nome;
private List<Cidade> cidades;
// getters e setters
}
Repare que existe a anotação @Cache. É ela quem determina que essa entidade deve ser colocada em cache.
Quando a entidade for consultada, o Hibernate irá guardá-la em memória e, quando precisar consultar essa entidade pelo identificador, ele irá verificar se a entidade já está no cache antes de buscar no banco de dados. E como você sabe, acesso em memória é muito mais rápido que acesso em um banco de dados externo.
A propriedade usage determina a estratégia de concorrência que deve ser usada. Essa estratégia, basicamente, controla quem está alterando e quem pode alterar ao mesmo tempo uma entidade no cache.
Deixei definido como CacheConcurrencyStrategy.NONSTRICT_READ_WRITE, que diz que iremos eventualmente editar essa entidade e que o controle de concorrência pode ser mais “simples”, pois é muito pouco provável que dois processos estejam alterando ao mesmo tempo essa entidade.
A mesma anotação existe na entidade Cidade, como você pode ver no código-fonte do exemplo.
Quando mandamos salvar a nota fiscal eletrônica, observamos que são feitas duas interações com o banco de dados. Uma para inserir a nota e outra para buscar todos os estados. Essa última consulta é realizada para remontar a tela e a caixa de seleção dos estados. Veja abaixo:
Hibernate:
insert
into
nfe
(codigo_cidade, descricao, valor)
values
(?, ?, ?)
Hibernate:
select
estado0_.codigo as codigo1_1_,
estado0_.nome as nome2_1_
from
estado estado0_
Vamos agora desabilitar o cache e ver o que acontece nessas consultas. Para desabilitar, vamos apenas comentar a anotação @Cache nas entidades Estado e Cidade.
@Entity
@Table(name = "estado")
//@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public class Estado implements Serializable {
private static final long serialVersionUID = 1L;
private Long codigo;
private String nome;
private List<Cidade> cidades;
// getters e setters
}
Reinicie o servidor para que seja feito novamente o deploy da aplicação e veja a quantidade de interações com o banco de dados dessa vez.
Hibernate:
select
estado0_.codigo as codigo1_1_0_,
estado0_.nome as nome2_1_0_
from
estado estado0_
where
estado0_.codigo=?
Hibernate:
select
cidade0_.codigo as codigo1_0_0_,
cidade0_.codigo_estado as codigo_e3_0_0_,
cidade0_.nome as nome2_0_0_
from
cidade cidade0_
where
cidade0_.codigo=?
Hibernate:
select
cidade0_.codigo as codigo1_0_0_,
cidade0_.codigo_estado as codigo_e3_0_0_,
cidade0_.nome as nome2_0_0_
from
cidade cidade0_
where
cidade0_.codigo=?
Hibernate:
insert
into
nfe
(codigo_cidade, descricao, valor)
values
(?, ?, ?)
Hibernate:
select
estado0_.codigo as codigo1_1_,
estado0_.nome as nome2_1_
from
estado estado0_
Uma pouquinho a mais, não foi? As duas primeiras são relacionadas aos converters do JSF e a outra é executada pelo próprio Hibernate antes de salvar a nota fiscal para determinar a cidade.
Com o cache reduzimos em 60% a ida ao banco de dados nesse exemplo. Ou seja, de 5 interações sem o cache fazemos apenas 2 com ele.
Isso pode ser muito bom se essas consultas forem lentas. Mas também requerem alguns cuidados, pois você precisa calcular a quantidade de memória que será necessário no seu servidor, por exemplo.
Deixe seu comentário sobre o que você achou e me fale se você já usou o cache de 2º nível em algum projeto seu ou pretende usar.
Acesse ou baixe o código-fonte completo deste artigo no GitHub.
Para aprender mais sobre JPA e Hibernate, conheça nosso curso online de JPA e Hibernate, que é completo e substitui a necessidade de cursos presenciais.






Olá,
o que você achou deste conteúdo? Conte nos comentários.