
Gostaria de conhecer um framework que vai mudar (pra melhor) a forma como você implementa a camada de persistência de seus projetos Java?
Não importa se você trabalha com o conceito de DAO ou Repositório, a questão é que você pode ser muito mais produtivo na hora de programar sua camada de persistência se utilizar o Spring Data JPA.
Se você usa JPA, acredito que vai gostar bastante dele. Então continue aqui comigo para aprender mais sobre:
- O que é o Spring Data JPA
- Como usar o
JPARepositorye ser muito produtivo - Criar consultas sem escrevê-las, só pela assinatura do método (curioso isso, não acha?)
- Utilizar JPQL através da anotação
@Query
Vamos lá?
O que é Spring Data JPA?
O Spring Data JPA é um framework que nasceu para facilitar a criação dos nossos repositórios.
Ele faz isso nos liberando de ter que implementar as interfaces referentes aos nossos repositórios (ou DAOs), e também já deixando pré-implementado algumas funcionalidades como, por exemplo, de ordenação das consultas e de paginação de registros.
Ele (o Spring Data JPA) é, na verdade, um projeto dentro de um outro maior que é o Spring Data. O Spring Data tem por objetivo facilitar nosso trabalho com persistência de dados de uma forma geral. E além do Spring Data JPA, ele possui vários outros projetos:
- Spring Data Commons
- Spring Data Gemfire
- Spring Data KeyValue
- Spring Data LDAP
- Spring Data MongoDB
- Spring Data REST
- Spring Data Redis
- Spring Data for Apache Cassandra
…mas, provavelmente, o mais utilizado desses é o Spring Data JPA, que é o nosso assunto aqui.
Configurando o Spring Data JPA
A gente vai trabalhar aqui com o Spring Boot, e em projetos com ele o Spring Data JPA já vem configurado através de convenções. Essa é uma dobradinha muito boa porque, além de sermos produtivos em nossa camada de persistência, ficamos também na parte de configurações.
No final do artigo vou disponibilizar o código-fonte pra você, mas vou adiantar aqui o que é necessário criar para seguir com os exemplos que irei mostrar. Lembrando que é um projeto Maven.
Você vai precisar das seguintes dependências no pom.xml:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> <dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency>
Ainda no pom.xml, é necessária a tag parent com referência ao Spring Boot:
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.4.3.RELEASE</version> </parent>
Depois do pom.xml configurado, você vai precisar também de uma classe como a que está abaixo para poder iniciar a aplicação:
@SpringBootApplication
public class ArtigoSpringDataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(Aplicacao.class, args);
}
}
Para você ter uma pequena ideia de quanto a gente economizou com a configuração do JPA – sem falar nas outras coisas que também já ficam configuradas por tabela como segurança, templates, etc. -, você pode olhar o código-fonte de um artigo anterior, sobre Spring Security, onde eu utilizei JPA e não fiz o uso do Spring Boot.
Interface JPARepository
Você já chegou a fazer algum repositório (ou DAO) genérico com os métodos buscar, salvar (ou atualizar) e remover? Pois é, essa interface é mais ou menos isso.
Ela tem todos os métodos que a gente precisa para fazer um CRUD (criar, ler, atualizar, deletar). Nós vamos usá-la agora pra que você veja o quanto é simples.
Mas antes, vamos construir a nossa entidade:
@Entity
public class Produto implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
private Long id;
private String nome;
private String descricao;
private boolean ativo;
@Temporal(TemporalType.TIMESTAMP)
private Date cadastro;
private int quantidade;
// getters e setters omitidos
}
É uma entidade bem simples mesmo porque o foco aqui é o Spring Data JPA.
Agora já podemos criar nosso repositório para a entidade Produto. Vamos chamá-lo de Produtos:
public interface Produtos extends JpaRepository<Produto, Long> {
}
É só isso que precisamos para poder utilizá-lo!
O que!? Está esperando eu criar a implementação da interface Produtos? Não, não precisa.
Quer dizer, precisa sim, mas quem vai disponibilizar uma pra gente, em tempo de execução, é o próprio Spring Data JPA!
Legal, não é mesmo?
A partir de agora você pode utilizar o repositório da mesma forma que qualquer outro que já tenha criado.
Para observar o funcionamento disso, vou criar um controlador com Spring MVC. Vou chamá-lo de ProdutosResource. A ideia é trabalhar com uma requisição web devolvendo somente JSON. Isso é mais que suficiente para fazermos os testes do nosso repositório.
@RestController
@RequestMapping("/produtos")
public class ProdutosResource {
@Autowired
private Produtos produtos;// <<< Repositório de produtos.
@GetMapping("/{id}")
public Produto buscar(@PathVariable Long id) {
return produtos.findOne(id);
}
@GetMapping
public List<Produto> pesquisar() {
return produtos.findAll();
}
@PostMapping
public Produto salvar(@RequestBody Produto produto) {
return produtos.save(produto);
}
@DeleteMapping("/{id}")
public void deletar(@PathVariable Long id) {
produtos.delete(id);
}
}
Agora basta fazermos requisições para o nosso controlador.
As requisições HTTP do tipo GET para os métodos buscar e pesquisar, você pode fazer em um navegador mesmo:
- http://localhost:8080/produtos
- http://localhost:8080/produtos/1
Para os meus testes, em particular, eu utilizei o Postman. Essa é uma extensão para o Google Chrome que nos ajuda, dentre outras coisas, a fazermos testes em nossos controladores. Assim posso testar, com facilidades, as requisições HTTP que são do tipo POST e DELETE.
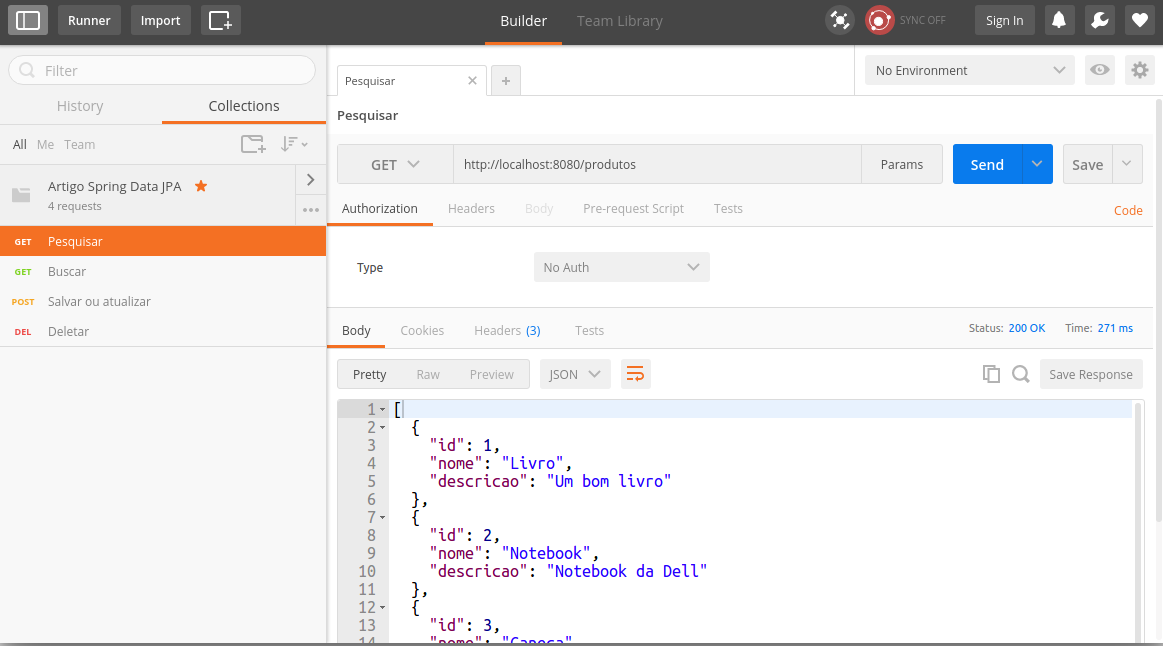
Se você vai utilizá-lo também, então pode baixar a coleção que criei – chamada “Artigo Spring Data JPA” – e importá-la no Postman através daquele botão Import no canto superior esquerdo. Dessa forma, vai ser só clicar no botão Send – em azul – para aquelas requisições que quiser testar.
Ordenação e paginação de registros
Além dos métodos CRUD, que ganhamos do Spring Data JPA, nós temos também os recursos de ordenação e paginação a nossa disposição.
Esses recursos estão presentes nas outras versões do método findAll. Primeiro vou mostrar a versão que faz a ordenação dos registros:
@GetMapping
public List<Produto> pesquisar(
@RequestParam(defaultValue = "nome") String ordenacao,
@RequestParam(defaultValue = "ASC") Sort.Direction direcao) {
return produtos.findAll(new Sort(direcao, ordenacao));
}
Na versão acima usamos o método que recebe o tipo Sort como parâmetro. Assim podemos receber da requisição a propriedade pela qual a consulta será ordenada e qual a direção (ascendente ou descendente).
Para testar essa nova versão, você pode fazer uma requisição para http://localhost:8080/produtos?ordenacao=nome&direcao=DESC. Pode usar tanto o Postman quanto o navegador.
Avançando mais um passo, temos a paginação também. Não é muito difícil implementar, mas é melhor ter pronto do que ter que fazer do zero, concorda?
Para paginação, usamos a versão do método findAll que recebe uma instância da interface Pageable – no caso, estamos passando uma instância da classe concreta PageRequest:
@GetMapping
public Page<Produto> pesquisar(
@RequestParam(defaultValue = "0") int pagina,
@RequestParam(defaultValue = "10") int porPagina,
@RequestParam(defaultValue = "nome") String ordenacao,
@RequestParam(defaultValue = "ASC") Sort.Direction direcao) {
return produtos.findAll(new PageRequest(pagina, porPagina, new Sort(direcao, ordenacao)));
}
Repare que essa versão do método findAll não devolve uma coleção de registros, e sim uma instância da interface Page. O legal disso é que, além da lista de produtos requisitada, também já temos disponíveis as seguintes informações:
getNumber: o número da páginagetSize: a quantidade de registros por páginagetNumberOfElements: a quantidade de registros retornados (quase igual agetSize, mas pode mudar para o caso de ser a última página)isFirst: se é a primeira páginaisLast: se é a última páginahasNext: se tem próxima páginahasPrevious: se tem página anteriorgetTotalPages: total de páginasgetTotalElements: total de registros
Repare também que estamos paginando e ordenando os registros. Para fazer mais esse teste você pode fazer uma requisição para http://localhost:8080/produtos?pagina=0&size=10.
Fazendo consultas com a assinatura do método
Até o momento vimos recursos do Spring Data JPA que são uma mão na roda. Porém o mais interessante desse framework é a criação de consultas a partir da assinatura do método.
Vamos a um exemplo básico. Nesse primeiro, iremos criar uma consulta que retorna o produto pelo nome.
public interface Produtos extends JpaRepository<Produto, Long> {
Produto findByNome(String nome);
}
Observando que também não precisamos dar uma implementação para esse método findByNome.
Repare que a nossa consulta começa com a palavra find. É preciso que seja com ela ou com:
- read
- get
- query
Após a palavra find e antes de By, eu poderia ter colocado mais alguma. Por exemplo, eu podia ter usado findProdutoByNome. Nesse caso, penso eu, que não é necessário, mas poderá ter algum outro que seja interessante pra você.
Logo depois do primeiro By é onde começam as condições, equivalente ao where do JPQL.
Nesse primeiro caso, usei somente o nome da propriedade “nome”. Com isso, o Spring Data entendeu que ele deve buscar um produto que seja igual ao que for passado no primeiro parâmetro (que, por um acaso, se chama “nome” também).
Deixa eu te mostrar agora um exemplo com uma condição where mais explicita:
public interface Produtos extends JpaRepository<Produto, Long> {
...
List<Produto> findByNomeStartingWith(String nome);
}
Esse muda duas coisas em relação ao anterior. Primeiro que ele está usando a condição StartingWith e outro que ele devolve uma lista de produtos.
Essa condição diz ao Spring Data para consultar por todos os produtos que começarem com a string passada no primeiro parâmetro. O próprio Spring Data JPA vai se encarregar de colocar o sinal de percentual.
Podemos ainda ordenar os registros assim:
public interface Produtos extends JpaRepository<Produto, Long> {
...
List<Produto> findByNomeStartingWithOrderByNome(String nome);
}
Agora que expliquei como as assinaturas dos métodos devem ser estruturadas, vou deixar aqui mais alguns exemplos pra você:
public interface Produtos extends JpaRepository<Produto, Long> {
Produto findByNome(String nome);
// Equivalente ao like, mas não precisamos nos preocupar com o sinal de percentual.
// Podemos usar também EndingWith, Containing.
List<Produto> findByNomeStartingWith(String nome);
// Ordenando pelo nome.
List<Produto> findByNomeStartingWithOrderByNome(String nome);
// Não levar em consideração a caixa.
List<Produto> findByNomeStartingWithIgnoreCase(String nome);
// Pesquisando por duas propriedades: nome e ativo.
List<Produto> findByNomeStartingWithIgnoreCaseAndAtivoEquals(String nome, boolean ativo);
// Nesse caso, precisamos usar o sinal de percentual em nossas consultas.
List<Produto> findByNomeLike(String nome);
// Podemos usar também IsNotNull ou NotNull.
List<Produto> findByDescricaoIsNull();
// Quando você quer negar o que passa no parâmetro
List<Produto> findByNomeNot(String nome);
// Todos os produtos com os IDs passados no varargs. Poderia usar NotIn para negar os IDs.
List<Produto> findByIdIn(Long... ids);
// Todos onde a propriedade ativo é true. Poderia ser falso, usando False.
List<Produto> findByAtivoTrue();
// Buscar onde a data de cadastro é depois do parâmetro passado.
// Pode ser usado Before também.
List<Produto> findByCadastroAfter(Date data);
// Buscar onde a data cadastro está dentro de um período.
List<Produto> findByCadastroBetween(Date inicio, Date fim);
// Todos com quantidade "menor que". Poderia ser usado
// também LessThanEqual, GreaterThan, GreaterThanEqual.
List<Produto> findByQuantidadeLessThan(int quantidade);
}
Acredito que, seguindo os exemplos acima, dá para brincar bastante. :)
Utilizando JPQL através da anotação @Query
Acho o recurso, de criar consultas pela assinatura do método, incrível, mas ele não é bala de prata. Você, provavelmente, ainda vai precisar executar consultas com JPQL.
O time de desenvolvimento do Spring Data JPA, claro, sabia disso e incluíram a anotação @Query pra gente.
Veja como funciona:
public interface Produtos extends JpaRepository<Produto, Long> {
...
@Query("from Produto where nome like concat(?1, '%')")
List<Produto> pesquisarProdutos(String nome);
}
Como você já deve imaginar, nós não precisamos dar a implementação para este método.
O que precisamos criar é a consulta. Repare ainda que essa consulta recebe um parâmetro. Por causa disso o nosso método também deve receber um parâmetro, pois, o Spring Data JPA usará ele na hora de executá-la.
Importante notar também que o nome pesquisarProdutos foi um nome aleatório. Ele não precisa seguir regra alguma, pois, a consulta que vale é a que está na anotação.
Conclusão
Vimos aqui sobre o que, mais exatamente, é o Spring Data JPA.
Aprendemos a utilizar a interface JPARepository e depois como definir consultas criando somente a assinatura do método dentro da interface.
Minha programação ficou consideravelmente mais ágil depois do Spring Data JPA. Pelo que viu aqui, acha que isso vai acontecer (ou já acontece) com você também? Deixe aí nos comentários.
Pra finalizar, você deve ter percebido que falamos bastante de Spring Boot, percebeu?
Caso você queira aprender mais sobre ele, então pode baixar nosso e-book Produtividade no Desenvolvimento de Aplicações Web Com Spring Boot:

No mais, um abraço pra você e até uma próxima!
PS: você pode baixar o código-fonte de exemplo em nosso GitHub: http://github.com/algaworks/artigo-spring-data-jpa











Olá,
o que você achou deste conteúdo? Conte nos comentários.